1. Introduction
1.1. What is Databricks
Databricks is a single, cloud-based platform that can handle all of your data needs, which means it’s also a single platform on which your entire data team can collaborate. Not only does it unify and simplify your data systems, Databricks is fast, cost-effective and inherently scales to very large data. Databricks is available on top of your existing cloud, whether its Amazon Web Services (AWS), Microsoft Azure, Google Cloud or a combination of this. At Natural State (NS) we use Databricks on top of the Microsoft Azure Storage platform.
1.2. What is databricks used for?
Databricks is a platform where we can do one or more of the following:
- store our data
- handle both batched data and real-time data streams
- transform and organise data
- perform calculations on data
- query data
- analyse data
- use the data for machine learning and AI
- generate reports
At NS, we use Databricks for a whole variety of tasks. We use their notebooks to write code, join the notebooks to form tasks that can be co-joined to form pipelines, to write queries and to a (very) less extent, create visualizations.
When we are working with data using Databricks here at NS, Databricks in essence is reading data from storage and writing data to that storage, in this case the Azure Data Lake Storage Gen2 Storage.
1.3 Concept of data lake, data warehouse and data lakehouse
Data lake
A data lake is a single, centralized repository where you can store all your data, both structured and unstructured. A data lake enables your organization to quickly and more easily store, access and analyze a wide variety of data in a single location.
Data warehouse
A data warehouse is like a well-organized storage room. Data warehouses store structured data from a variety of different sources. Data is stored in a relational structure, meaning that data inside the warehouse is neatly organized into rows, columns and tables.
Data undergoes a process called data ingestion before getting stored in a data warehouse. Data ingestion involves collection, processing and preparing data for storage. Here’s how it works:
-
Extract data from various sources
-
Transform the data by cleaning, processing and converting it into the desired format.
-
Load the newly transformed data into your data warehouse.
Data Lakehouse
A data lakehouse is a data management architecture that combines key capabilities of data lakes and data warehouses. It brings the benefits of a data lake, such as low storage cost and broad data access, and the benefits of a data warehouse, such as data structures and management features.
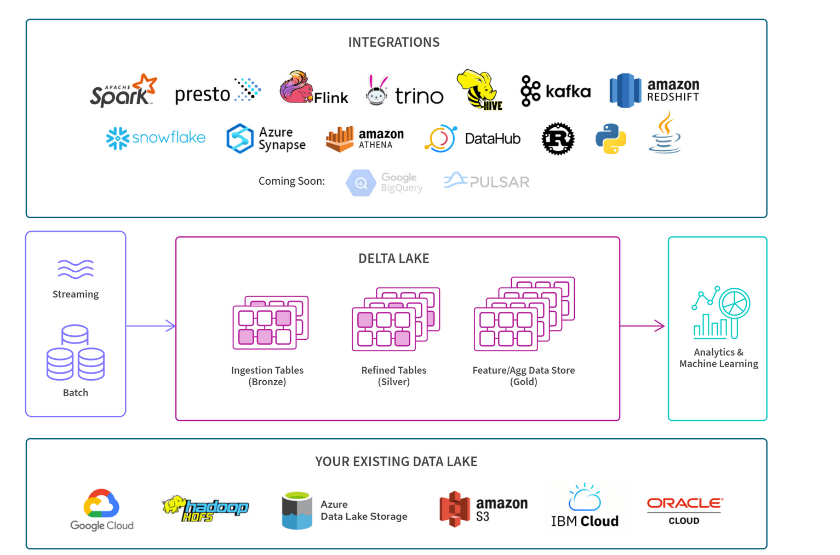
Delta Lake Architecture
Delta lake architecutre is an advanced and reliable data storage and processing framework built on top of a data lake. It extends the capabilities of traditional data lakes by providing ACID (Atomicity, Consistency, Isolation, Durability) transactional properties, schema enforcement, and data versioning.
In delta lake, data is organized into a set of Parquet files, which are stored in a distributed file system. It maintains metadata about these files, enabling defficient data management and query optimization. Delta lake also offers features like time travel, which allows users to access and revert to previous versions of data, and schema evolution, which enables schema updates without interrupting existing pipelines. This architecture enhances data reliability, data quality, and data governance, making it easier for organizations to maintain data integrity and consistency throughout the data lifecycle.
Delta lake is an extension of the data lakehouse.
1.4 The Azure Databricks Workspace UI
The Azure Databricks workspace UI is where an individual can access all their databricks azure objects. To get to the databricks workspace UI, you to to Azure Microsoft.
Once you sign in, you will be brought to an interface that looks like this:
Click the ns-ii-tech-dev-db-workspace.
Click on Launch Workspace.
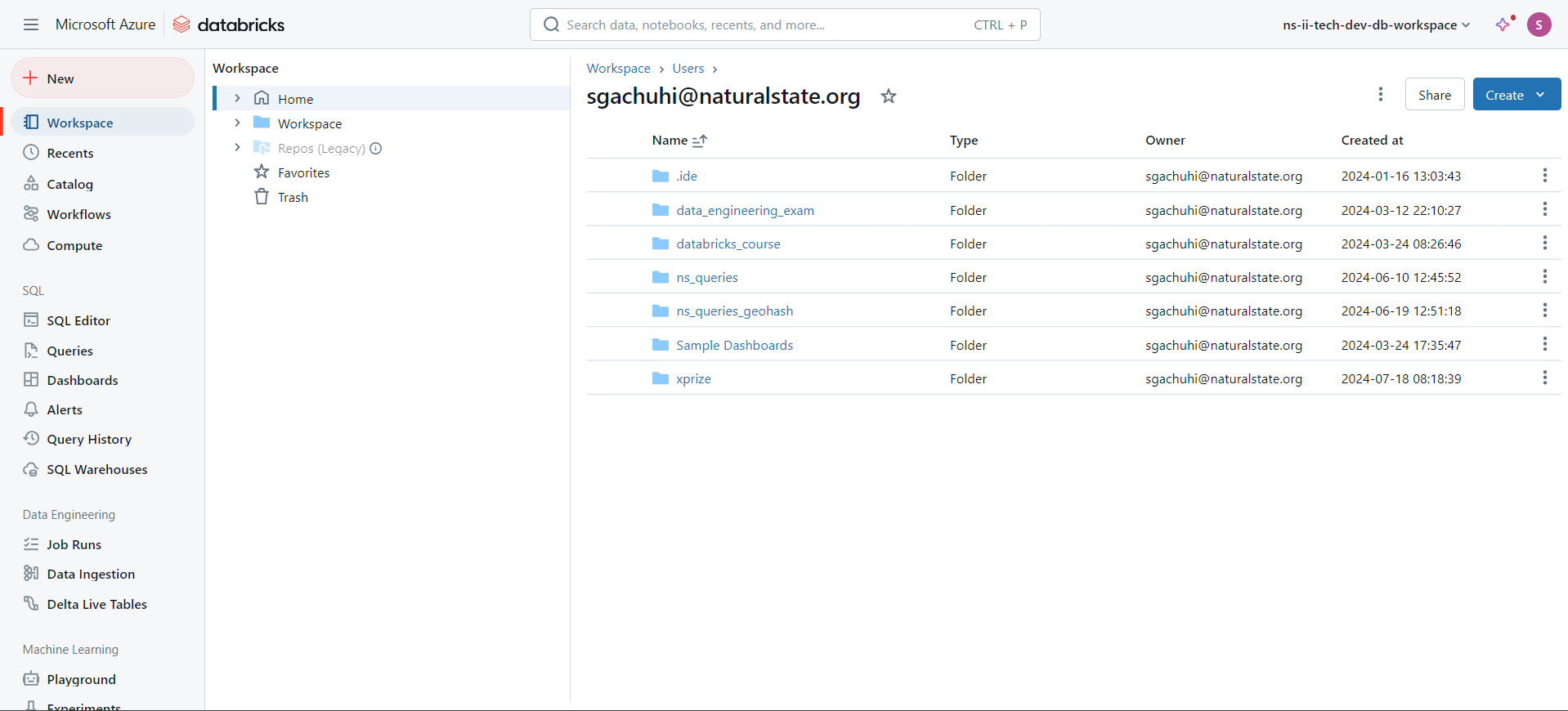
The above Azure Databricks workspace UI consists the following features:
- Sidebar
This contains the following tabs:
- Workspace
- Recents
- Data
- Workflows
- Compute
- SQL
The SQL section contains the following tabs:
- SQL Editor
- Queries
- Dashboards
- Alerts
- Query History
- SQL Warehouses
- Data Engineering
Contains:
- delta live tables
- Machine Learning
This section contains the following:
- Experiments
- Feature Store
- Models
- Serving
NB: Currently at Natural State (NS), we have to workspaces, the ns-ii-tech-dev-workspace and the ns-ii-tech-stg-workspace. These refer to the dev and staging environments respectively. The difference between the former and the latter is that the latter mirrors the production environment more closely. For data ingestion purposes, you will mostly be working at the ns-ii-tech-dev-workspace.